3.4 정보 접근하기
x86-64 cpu는 범용 레지스터 16개를 가지고 있다.
- 정수 또는 포인터(주소)를 저장
- 각 레지스터 크기는 64비트
- rdi, rsi, rdx, rcx, r8, r9
-> 함수 1~6번째 인자를 전달할 때 사용하는 레지스터 - rsp
-> 함수 7~ 번째 인자를 전달할 때 사용하는 레지스터
-> 7번째 인자부터는 stack을 통해 전달됨
-> rsp를 스택 포인터라고도 함 - rax
-> 함수 리턴값을 담는 레지스터

현재 레지스터 형태로 오기 까지
8086 cpu 시절에는 16비트짜리 레지스터 8개만 있었다.
ax, bx, cx, dx, si, di, bp, sp
IA32 cpu 시절에는 32비트짜리 레지스터로 바뀌었다.
eax, ebx, ecx, edx, esi, edi, ebp, esp
x86-64 cpu가 되면서 64비트짜리 레지스터로 바뀌었다.
rax, rbx, rcx, rdx, rsi, rdi, rbp, rsp
그리고 8개의 레지스터를 추가했다.
r8, r9, r10, r11, r12, r13, r14, r15
3.4.1 오퍼랜드 식별자

인스트럭션은 보통 오퍼랜드를 하나 이상 가진다.
오퍼랜드는 연산을 수행할 source값과 그 결과를 저장할 destination의 위치를 명시한다.
source값은 상수로 주어지거나 레지스터나 메모리로부터 읽을 수 있다.
결과값은 레지스터나 메모리에 저장된다.
x86-64의 오퍼랜드 타입
- immediate
- 즉시값
- 상수 그 자체
- 예) $10 $0xFF $-4
- 예) mov $0x1F, %eax
-> 숫자 31을 바로 %eax에 넣어라 (메모리 주소에 있는 값을 가져오는 것이 아니라 상수값 자체를 사용) - '$' 기호 다음 오는 숫자를 그대로 정수로 읽으면 됨
- 즉시값에 $기호를 넣는 이유 : 이 기호가 없으면 숫자가 메모리 주소로 해석될 수 있음
- register
- 레지스터에 저장된 값 참조
- 예) %rax %eax %r8d %bx
- 16개의 레지스터들의 하위 일부분인 8, 4, 2, 1바이트 중 하나의 레지스터를 가리킴
- memory
- 메모리에 있는 값 참조
- 예) (%rbx) 8(%rbp) (%rdi, %rsi, 4)
- 유효주소로 메모리 위치 접근
유효 주소(effective address)?
- 어셈블리어에서 메모리를 참조할 때 계산되는 최종 메모리 주소
- 어셈블리어는 메모리에 접근할 때 단순한 숫자 주소를 쓰는 게 아니라 조합된 방식을 쓰는 경우가 많음
- 유효주소 계산 공식 = Imm(base, index, scale) = immediate + base + index * scale
- base : 배열 시작 주소
- index : 배열의 인덱스
- scale : 인덱스에 곱해질 값 (1, 2, 4, 8만 가능)
- immediate(displacement) : 상수값
- 배열 시작 주소가 안 주어진 경우
- cpu는 그냥 0으로 간주하고 나머지 주소를 공식 그대로 계산함
- 이런 형태는 주로 전역 배열을 직접 접근할 때에 쓰임
- 컴파일러가 배열의 시작 주소를 이미 고정된 위치(심볼 주소)로 처리할 수 있기 때문에 명령어에서 따로 base 레지스터를 쓸 필요가 없음
- movl arr(, %rcx, 4), %eax 처럼 base 없이 index만으로 계산하는 명령어가 생성되기도 함
- 유효주소 계산 공식 = Imm(base, index, scale) = immediate + base + index * scale
- 예)
- movq (%rax), %rdx
-> base
(%rax가 가리키는 메모리 주소에 있는 값을 %rdx에 복사) - movq 8(%rax), %rdx
-> base + displacement
(%rax + 8바이트 떨어진 곳에 있는 값을 읽음) - movq (%rax, %rcx, 4), %rdx
-> base + index*scale
(%rax에 배열의 시작 주소가 저장되어있음, %rcx에 배열의 인덱스가 저장되어있음, 4는 요소의 크기(sizeof(int) 즉 4바이트), 해당 주소의 메모리 내용을 읽어와 %rdx에 저장)
즉 c언어로 치면 rdx = *(int64_t *)(&arr[rcx]) - movq 16(%r10, %rdx, 2), %rdx
-> base + index*scale + displacement
- movq (%rax), %rdx
- cpu는 이걸 계산해서 '실제 메모리 주소'로 바꿈
- 그렇게 최종적으로 계산된 주소를 유효주소라고 함
'메모리 참조' 오퍼랜드에서의 일반적인 주소지정방식 형태
Imm(rb, ri, s)
-> Imm + R[rb] + R[ri] * s가 유효 주소가 됨
- Imm : 상수 오프셋
- rb : 베이스 레지스터
- ri : 인덱스 레지스터(64bit)
- s : 배율(scale) 1, 2, 4, 8중 하나
오퍼랜드 타입 : 어셈블리 명령어에서 '연산 대상(operand)'의 종류가 무엇인지 구분하는 개념
(값이 상수, 레지스터, 메모리 중 어디에 있는가?)

주소지정방식 : 오퍼랜드가 메모리 참조일 때, 해당 메모리 주소를 어떻게 계산하는가의 개념
(이 메모리 주소를 어떻게 계산했는가?)

유효 주소 : 주소지정방식을 바탕으로 계산된 실제 메모리 주소값
3.4.2 데이터 이동 인스트럭션
가장 많이 사용되는 인스트럭션은 데이터를 한 위치에서 다른 위치로 복사하는 명령이다.
어셈블리에서 오퍼랜드를 유연하게 쓸 수 있게 설계된 덕분에 (레지스터, 메모리, 즉시값 등의 조합 가능) 데이터 인스트럭션이 더 간단해졌다.
예전 컴퓨터에서는 데이터를 이동할 때 필요한 명령어가 여러 개였다.
ISA가 복잡해지고 cpu도 각 명령어 마다 별도의 회로가 필요했다.
mov_reg_to_mem_8bit
mov_reg_to_mem_16bit
mov_imm_to_mem_8bit
mov_mem_to_reg_32bit
반면에 x86 계열에서 mov 명령어는 하나의 '동작 패턴'을 공유한다.
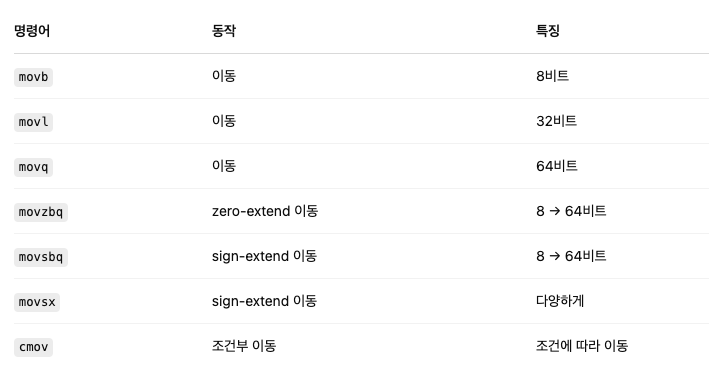
예를 들어 movb, movl, movq는 모두 '이동'이라는 동작을 하고 오퍼랜드 크기만 8, 32, 64비트로 다르다.
movzbq, movsbq, movsx, cmov 등의 명령어들도 마찬가지로 모두 내부적으로 하나의 '이동' 동작을 기반으로 하고 조건만 다르다.
movzbq (zero-extend byte to quadword)
8비트값을 64비트로 복사하되 상위 비트는 모두 0으로 채운다(zero-extension)
예) unsigned char 같은 부호 없는 작은 정수 타입을 더 큰 레지스터로 옮길 때 사용
movzbq %al, %rax
unsigned char x; unint64_t y = x;
movsbq (sign-extend byte to quadword)
8비트값을 64비트로 복사하되 부호 비트를 확장해서 채운다(sign-extension)
예) char -> long 같은 부호 있는 확장
movsbq %al, %rax
char x = -3; int64_t y = x;
movsx (sign-extend)
movsbq와 같이 크기가 고정되어있지 않음
크기별 접미사 표시할 없이 작은 크기->큰 크기로 옮긴다는 조합만 잘 맞춰주면 됨
예) movsx %ax, %eax
cmov (conditional move)
어떤 조건이 참일 때만 값을 이동
예) cmovCC src, dst
참고 ; c언어 기본 타입 크기 (x86-64)


표준 고정 크기 타입 (stdint.h에서 제공)
-> 정확한 크기의 타입으로 바꿔줘서 어셈블리 연계 코딩할 때 좋다고 함
참고; 컴파일러는 데이터 타입의 실제 크기를 측정해서 어셈블리 접미사를 붙인다.
| 데이터 크기 | 8byte | 4byte | 2byte | 1byte |
| c언어 타입 | long/double | int/float | short | char |
| 접미사 | q/d | l/ss | w | b |
| 사용되는 레지스터 | %rax/SSE | %eax/SSE | %ax | %al |
데이터 타입 크기가 같아도 정수/실수는 다른 접미사를 붙여줌
정수/실수 연산이 cpu 내에서 다르게 처리되기 때문
정수(char, int, short, long..)는 범용 레지스터 (%rax, %eax, %ax, %al)에서 처리
실수(float, double..)는 SSE 레지스터(XMM)라는 부동소수점 레지스터에서 처리됨
mov 명령어의 접미사 결정 기준?
movX의 접미사 X는 "데이터를 몇 바이트 옮길 건지"에 따라 결정되는데,
보통 레지스터가 소스나 목적지에 있으면 그 레지스터 크기가 기준이 된다.
메모리 오퍼랜드의 경우 그 자체로는 읽어오는 데이터의 크기를 알 수 없는 반면에.. 레지스터는 바이트별로 이름이 딱 정해져있으므로
소스나 목적지로 설정된 레지스터 이름만 봐도 아 몇 바이트 옮기는거구나 추측할 수 있기 때문이다.
따라서 소스가 메모리 참조일 때는 접미사나 함께 쓰이는 레지스터가 데이터 크기를 결정한다.
연습문제 3.2
어셈블리 언어가 주어지고 오퍼랜드를 고려하여 적절한 접미사를 삽입하라고 되어있다.
mov_ %eax, (%rsp)의 경우 eax 레지스터에서 데이터를 읽어와 메모리에 복사하라는 뜻이다. eax레지스터에서 4바이트를 읽어왔으므로 이동하는 데이터 크기는 4바이트일 것이다. 따라서 접미사 l을 써야 한다.
mov_ (%rax), %dx의 경우 메모리에서 데이터를 읽어와 dx레지스터에 복사하라는 뜻이다. dx레지스터에 2바이트를 복사할 것이므로 이동하는 데이터 크기는 2바이트일 것이다. 따라서 접미사 w를 써야 한다.
데이터 이동 인스트럭션(mov)의 기본 형태
mov source destination예) movsbq %al %rax
mov 명령어는 오퍼랜드의 크기, 부동 소수점, 부호 존재 여부에 따라 접미사가 다르게 붙는다.
source 오퍼랜드는 상수, 레지스터 저장 값, 메모리 저장 값이 될 수 있다.
destination 오퍼랜드는 레지스터 주소, 메모리 주소가 될 수 있다.
x86-64 데이터 이동 인스트럭션의 두 오퍼랜드가 모두 메모리가 될 수 없는 이유
x86에서는
mov (%rax), (%rbx)
와 같이 메모리->메모리로 데이터가 이동할 수 없다.
mov (%rax), %rcx
mov %rcx, (%rbx)
이렇게 꼭 레지스터를 거쳐가야 한다.
데이터가 여기서 저기로 복사되려면 당연하게도 먼저 cpu가 어디서 어디로 어떤 데이터를 복사해야 하는지 이해해야 한다.
그런데 cpu는 레지스터랑만 상호작용하기 때문에 결론적으로 레지스터를 꼭 거쳐야 하는 것.
cpu가 멀리 있는 메모리까지 가서 데이터를 읽어와서 연산하고 다시 메모리에 갖다넣는 건 말도 안 되기 때문에.. 일단 메모리에서 레지스터로 데이터를 가져와야 alu 연산을 하든 agu로 메모리 주소를 계산하든 뭔갈 속도있게 처리할 수 있다.
데이터 이동 인스트럭션(mov)의 특징
그럼 우리는 x86에서 특정 메모리 위치에서 다른 메모리 위치로 어떤 값을 복사하기 위해서는 인스트럭션 2개가 필요하다는 사실을 자연스레 알게 되었다. 이게 데이터 이동 인스트럭션의 첫 번째 특징이다.
✔️ 데이터 이동을 위해서는 mov를 두 번 해야 함
1. source값을 레지스터에 적재하기
mov (%rax), %rcx
2. 레지스터 값을 destination에 쓰기
mov %rcx, (%rbx)
✔️ mov는 딱 지정된 바이트만 건드린다. 예를 들어
movb $0xAA, %al
이건 %rax 전체를 바꾸는 게 아니다. %rax의 하위 8비트인 %al만 바꾸고 나머지 상위 비트는 그대로 둔다.
즉 mov는 명시된 크기 만큼만 덮어쓴다.

앞서 글을 시작할 때 레지스터 하나는 여러 이름으로 접근 가능하다고 배웠다.
첫 번째 레지스터를 %rax라는 이름으로 접근하면 64비트(레지스터 전체 공간)가 바뀌고
%eax로 접근하면 하위 32비트만 바뀌고 나머지 공간은 바뀌지 않는다.
마찬가지로 movb, movw, movq도 동일하게 접근한 범위만 바뀐다.
그러나 movl은 예외가 있음 : movl이 레지스터를 목적지로 가지면 이 레지스터의 상위 4바이트도 0으로 설정됨
즉 movl로 레지스터에 쓸 경우에는 암묵적으로 64비트 전체를 제로확장해서 덮어쓴다.
x86-64에서 64비트 상수값을 레지스터에 로드할 때
movq $1234, %rax
상수 1234를 64비트 레지스터 %rax에 넣어라 라는 명령처럼 보이지만 사실은 진짜 64비트 상수를 마음대로 못 넣음
32비트 상수만 허용되고 나머지 상위 32비트는 부호 확장해서 채워짐
부호 확장이란 32비트 상수를 64비트로 만들 때, 가장 왼쪽 비트(부호 비트)를 복사해서 상위32비트를 채우는 방식
참고; movzlq는 왜 없는가??
movzbq (zero-extend 8->64비트)
movsbq (sign-extend 8->64비트)
movzwq (zero-extend 16->64비트)
는 있는데 zero-extend 32->64비트는 왜 없나?
x86-64에서 movl명령어 자체가 자동으로 64비트 레지스터에 zero-extend하는 효과가 있기 때문이다.
x86-64에서 movl의 목적지로 레지스터를 주면 상위 32비트(%rax의 상위 부분)을 무조건 0으로 클리어한다.
즉 자동으로 zero-extension이 된다.
반면 movl은 sign-extension은 안 해서 부호확장을 해주려면 movslq명령어를 써야 한다.
이러한 예외가 생긴 이유는 관습 때문이다.
어떤 레지스터를 위한 32비트값을 생성하는 인스트럭션은 레지스터의 상위 바이트들 또한 0으로 설정하도록 하는 관습이 있었다.
movz : 목적지의 남은 바이트들을 모두 0으로 채움
movs : 목적지의 남은 바이트들을 모두 부호 비트로 채움
연습문제 3.3
해당 어셈블리 명령어가 에러 메시지를 생성하는 이유를 찾는 문제
movb $0xF, (%ebx) # x86-64에서 32비트 레지스터(%ebx)를 주소 참조용으로 사용하기에는 크기가 작다. 무조건 64비트 레지스터를 사용해서 주소 계산을 해야 한다.
movl %rax, (%rsp) # 레지스터 크기가 8바이트이기 때문에 접미사가 q여야 함
movw (%rax),4(%rsp) # 메모리-메모리로 데이터 바로 이동 불가
movb %al,%sl # sl이라는 이름의 레지스터는 존재하지 않음
movq %rax,$0x123 # 목적지는 상수가 될 수 없음
movl %eax,%rdx # mov명령어는 소스랑 목적지 크기가 항상 일치해야 하는데 eax는 4바이트고 rdx는 8바이트라서 틀림. 그리고 접미사가 l이니까 둘 중에 rdx가 바뀌어야 함
movb %si, 8(%rbp) # 소스 레지스터가 2바이트이기 때문에 접미사가 w여야 함
3.4.3 데이터 이동 예제
c코드의 *xp = y, x = *xp 와 같은 포인터 연산이
어셈블리에서는 mov 명령어로 메모리-레지스터 간 데이터 이동으로 구현된다는 걸 보여주는 예제
그리고 리턴값은 %rax 레지스터로 전달됨
//c언어
long exchange(long *xp, long y)
{
long x = *xp;
*xp = y;
return x;
}//어셈블리어
0 exchange:
1 movq (%rdi), %rax //rdi 안에 있는 주소에 있는 8바이트 값을 rax에 저장하라
2 movq %rsi, (%rdi) //rsi 안에 있는 8바이트 값을 rdi 안에 있는 주소에 해당하는 메모리 위치에 저장하라
3 ret- 프로시저가 시작되면 매개변수 xp값은 %rdi에, y값은 %rsi에 저장된다.
- 프로시저 인자로 포인터가 들어왔다는 것은 어떤 값이 전달됐다는 의미일까? 주소?값?참조?
- 메모리 주소값이 함수에 전달됐다는 의미이다. 포인터도 결국 메모리의 주소'값'을 가지고 있기 때문이다.
- 즉 포인터를 인자로 넘긴다는 건 메모리 주소값을 함수에 넘겨서 함수 내부에서 그 주소를 통해 원래 데이터를 직접 수정할 수 있게 해준다는 뜻이다.
- 프로시저 인자로 포인터가 들어왔다는 것은 어떤 값이 전달됐다는 의미일까? 주소?값?참조?
- x를 메모리에서 읽어서 %rax에 저장한다.
- ret만 해주면 자동으로 rax에 있는 값이 리턴된다.
연습문제 3.4
sp는 %rdi, dp는 %rsi에 저장되어있음
sp, dp의 자료형이 다음과 같이 주어질 때
1. 메모리에서 sp를 읽어와 dest_t 타입으로 변환 (필요하면 확장/축소)
- 큰 타입으로 변환하면 확장(extend) 필요 : signed 타입이면 movsx, unsigned 타입이면 movzx를 사용함
- 작은 타입으로 변환하면 확장 필요 x : 별도의 확장 명령어가 필요 없음 그냥 mov를 쓰면 자동으로 하위 비트가 잘림
- c언어에서 명시적으로 unsigned라는 표시가 안 되어있으면 모두 signed타입임
2. 레지스터 %rax에 쓰기 (%rax, %eax, %ax, %al 중 하나)
//sp, dp가 typedef로 선언된 자료형을 가지고 있음
src_t *sp;
dest_t *dp;
//sp가 가리키는 값을 읽고 그 값을 dest_t타입으로 바꾼 뒤 dp가 가리키는 위치에 저장하라
*dp = (dest_t) *sp;| src_t | dest_t | Instruction | 설명 |
| long | long | movq (%rdi), %rax movq %rax, (%rsi) |
%rdi에서 8바이트 읽기 8바이트를 %rsi에 저장 |
| char | int | movsbl (%rdi), %eax movl %eax, (%rsi) |
%rdi에서 1바이트 읽어서 4바이트로 부호 확장 4바이트를 %rsi에 저장 |
| char | unsigned | movsbl (%rdi), %eax movl %eax, (%rsi) |
%rdi에서 1바이트 읽어서 4바이트로 부호 확장 4바이트를 %rsi에 저장 |
| unsigned char | long | movq %rax, (%rsi) |
%rdi에서 1바이트 읽어서 8바이트로 부호 없는 확장 8바이트를 %rsi에 저장 * long으로 바꾸는 건데 왜 movzbq가 아니라 movzbl인가? -> movl만으로도 상위 32비트를 0으로 자동으로 클리어해서 64비트가 이미 만들어져있음. 그래서 저장할 때는 movl이랑 %eax으로 32비트를 저장하고 읽을 때는 movq, %rax로 읽음 (효율성 측면에서도 이렇게 하는 게 유리하다고 함) |
| int | char | movb %al, (%rsi) |
%rdi에서 그 중 1바이트만 읽어서 %rsi에 저장 * 큰 데이터 타입에서 작은 데이터 타입으로 바꿀 때는 큰 데이터 타입 그대로 읽어와서 작은 데이터 타입만큼만 잘라서 읽은 결과를 복사함 |
| unsigned | unsigned char | movl (%rdi), %eax movb %al, (%rsi) |
%rdi에서 그 중 1바이트만 읽어서 %rsi에 저장 |
| char | short | movsbw (%rdi), %ax movw |
%rdi에서 1바이트 읽어서 2바이트로 부호 확장 2바이트를 %rsi에 저장 |
mov할 때 부호확장(movs)이 필요한 이유? / 2의 보수로 표현된 음수값을 더 큰 레지스터에 안전하게 복사하는 방법?
- signed에서 작은 타입 -> 큰 타입으로 복사할 때는 부호 확장을 해줘야 함 (부호확장이란 상위 비트들을 모두 부호 비트로 채워주는 것)
그래서 movsbq, movswl 등 movsx계열 명령어를 써야 함 - 반면 unsigned에서 작은 타입 -> 큰 타입으로 복사할 때는 부호가 없어서 상위 비트들을 그냥 0으로 채워줘도 됨
그래서 movzx계열 명령어를 사용하는 것 - 그렇다면 signed 작은 타입을 -> unsigned 큰 타입으로 복사하려면 movsx, movzx 계열 중 뭘 써야 할까?
movsx를 사용해야 함. signed -> unsigned로 형변환을 하더라도 그 값을 먼저 signed로 해석한 뒤 unsigned 타입으로 변환해야 하기 때문- 예를 들어 -3은 8비트 2의 보수로 11111101인데 얘를 16비트로 확장해보자
- 먼저 부호를 유지하면서 16비트로 확장하면 1111111111111101이 됨
- 이 값을 해석만 unsigned int로 하면 된다.
- 즉 비트 값은 바꾸지 않고 그대로 두고 signed가 아닌 unsigned 타입으로 간주해서 읽는다.
예)
8비트
-6 = 111111010 = 0xFA
6 = 00000110
64비트
그냥 복사했을 때 : 0x00000000000000FA = 250
얻고 싶은 값 : 0xFFFFFFFFFFFFFFFA = -6
movsbq %al, %rax
- %al : 8비트 -6 = 111111010 = 0xFA
- %rax : 64비트
- movsbq : 8비트 부호비트 (맨 앞 1)을 복사해서 상위 56비트를 채워줌
이처럼
signed에서 작은 타입 -> 큰 타입으로 변환할 때는 movsx계열 (movsbq, movswq, movslq 등)을 써서 상위 비트들을 모두 부호 비트로 채워줘야 하고
unsigned에서 작은 타입 -> 큰 타입으로 변환할 때는 movzx계열을 써서 상위 비트들을 0으로 채워줘야 함